Where are we at, and what is the future?
Due to the size of this most recent item, we took a break from the blog last month. This month, we talk about machine vision systems and artificial intelligence (AI). a topic that has received a lot of attention since the release of AI language models like ChatGPT and AI picture models like DALLE. For vision systems, AI is beginning to gain traction, but what exactly is it? And is it practical?
Where are we at?
Let’s begin where we left off. The name “AI” is an addition to a machine vision method that has been used for twenty years but has only recently gained popularity (or, should we say, reached the point of widespread adoption). Early in the new millennium, we offered vision systems that used low-level neural networks for feature separation and categorization. These were mostly employed for character verification and straightforward segmentation. These networks had rudimentary functionality. But the method we followed to train the network back then is the same as it is today—only on a far bigger scale. The phrase artificial intelligence has replaced the word “neural network” that we used back then.
The phrase “artificial intelligence” was created because the network possesses some degree of “intelligence” that allows it to pick up new information through iterative training levels and learn by doing. The first studies on computer vision AI found that the way neurons react to different inputs in human vision had a hierarchical structure. Neurons pick up on basic elements like edges, which feed into more sophisticated features like shapes, which in turn feed into more sophisticated visual representations. As a result, the brain can see “images” made up of discrete blocks. Pixel data in industrial vision systems can be viewed as the foundation of synthetic picture data. Millions of distinct pixels, each with a unique greyscale or color, are conveyed as pixels from the image sensor to the CPU. For instance, a line is just a line of pixels with the same level, with the borders varying in grey level from pixel to pixel from one position to the next.
Neural systems Artificial intelligence (AI) vision tries to mimic how the human brain learns edges, forms, and structures. Processing units are arranged in layers in neural networks. Receiving input signals and transmitting them to the next layer and subsequent layers is the only job of the first layer. The following layers are referred to as “hidden layers” since the user cannot see them right away. These handle the actual signal processing. The last layer directly encodes the class membership of the input pattern by translating the internal representation of the pattern produced by this processing into an output signal. These kinds of neural networks are capable of realizing arbitrary complex correlations between the values of features and the names of classes. The relationship included in the network is derived by special training algorithms from a collection of training patterns, and it depends on the weights of the connections between the layers and the number of layers. The end result is a non-linear “web” of links between the networks. All of this is an effort to simulate how learning occurs in the brain.
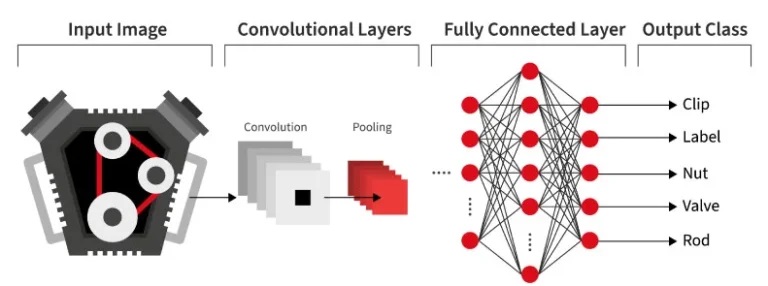
With this knowledge, visual engineering researchers have focused their efforts on accurately simulating the human neural circuitry, which is how artificial intelligence (AI) was created. Similar to their biological counterparts, computer vision systems use a hierarchical method to perceive and analyze visual data. Traditional machine vision inspection is carried on in this way, but AI needs a comprehensive view of all the data to compare against and make advancements in.
Therefore, the development of artificial intelligence and deep learning vision systems has exploded over the past five years. These systems are built on the advancement of neural networks in computer vision, together with the advancement of AI in other branches of software engineering. Every one of them is typically based on an automatic differentiation library that implements neural networks in a straightforward, simple-to-configure manner. To help identify the root cause of a quality control issue, deep learning AI vision solutions combine artificial intelligence-driven defect discovery with visual and statistical correlations.
As a result of the requirement for vision data for training becoming a crucial component for all AI vision systems as opposed to deploying conventional machine vision algorithms, vision systems have evolved into manufacturing AI and data-gathering platforms in order to stay up with this progress. Though not to the same extent as deep learning, traditional vision algorithms still require image data for development. This means that from the development stage of the vision project all the way through production quality control deployment on the shop floor, vision platforms have evolved to integrate visual and parametric data into a single digital thread.
The growth of vendors offering data-gathering “AI platforms” is occurring at the same time as the potential application of AI in vision systems is multiplying. These systems don’t represent a fundamental advance in image processing or a glaring departure from conventional machine vision; rather, they serve as a housekeeping exercise for image collecting, segmentation, and human classification before the neural network is applied. Notably, the majority of these businesses have “AI” in their names. These platforms provide easy image submission to the network for the computation of the neural algorithm as well as clear visual presentation. Nevertheless, they all share the same general architecture.
The deep learning frameworks – Tensorflow or PyTorch – what are they?
The two primary deep learning frameworks used by those who create machine vision AI systems are Tensorflow and PyTorch. Google and Facebook, respectively, created each. They serve as the foundation for creating low-level AI models, which are typically layered with a graphical user interface (GUI) for image sorting.
Dataflow programming across a range of workloads is best suited for TensorFlow, a symbolic math library. For modeling and teaching, it offers a wide range of abstraction levels. It’s a promising and expanding deep-learning option for makers of machine vision systems. It offers a versatile and complete ecosystem of libraries, tools, and community resources for creating and delivering machine-learning apps. A forerunner of Tensorflow, Keras, has recently been included in the framework by Tensorflow.
Built on Python and Torch, PyTorch is a highly efficient deep-learning tensor framework. Applications that make use of graphics processing units (GPUs) and central processing units (CPUs) are its main use cases. Because it uses dynamic computation networks and is wholly written in Python, vision system providers choose PyTorch over other Deep Learning frameworks like TensorFlow and Keras. It enables academics, software developers, and debuggers of neural networks to test and run specific parts of code in real-time. As a result, users do not need to wait for the development of the full code before judging whether or not a specific section of it functions.
Whichever solution is used for deployment, the same pros and cons apply in general to machine vision solutions utilizing deep learning.
What are the pros and cons of using artificial intelligence deep learning in machine vision systems?
Well, there are a few key takeaways when considering using artificial intelligence deep learning in vision systems. These offer pros and cons when considering whether AI is the appropriate tool for industrial vision system deployment.
Cons
– Industrial machine vision systems must have high yield, Therefore, instead of accepting a certain false failure rate, we are talking about fault identification that is 100 percent accurate. When setting up vision systems, there is always a trade-off to make sure you err on the side of caution so that real failures will always be picked up and rejected by the system. However, due to the fact that the user has no control over the processing functionality that has determined what constitutes a failure, AI inspection yields are far from perfect. The outcome is simply indicated as pass or fail. The neural network has been taught from a wide range of successes and failures. This “low” yield—which is still above 96 percent—satisfies most deep learning requirements—such as those for e-commerce, language models, and general computer vision—but is unacceptable for most industrial machine vision application requirements. When considering the use of deep learning, this must be taken into account.
– It takes a lot of image data. The AI machine vision system may require thousands or even tens of thousands of training images to begin the process. This is not to be understated. Also, consider the implications for deployment in a manufacturing facility: before the learning phase can begin, you must install and operate the system to collect data. This is not the case with conventional machine vision solutions; development can be finished prior to deployment, reducing time to market.
– Most processing is completed on reduced-resolution images. The majority of deep learning vision systems, if not all of them, will reduce the image size to a manageable size so that they can process it quickly. As a result, from an image with a mega-pixel resolution down to a few hundred pixels, the resolution immediately decreases. The loss and compromise of data
– There are no existing data sets for the specific vision system task. There are typically no pre-defined data sets from which to work, in contrast to AI deep learning vision systems used in other industries, such as crowd scene detection or driverless cars. If you want to quickly develop an AI vision system that can identify “cats,” “dogs,” or “humans,” there are data sources available in those industries. We always look at a specific widget or part fault in industrial machine vision without a predetermined visual data source. As a result, image data collection, sorting, and training are necessary.
– You need good, bad, and test images. When selecting the images for processing, you must exercise extreme caution. In the 10,000 images that make up the “good” pile, a “bad” image will train the network to distinguish between good and bad. As a result, the quality of the deep learning system is only limited by the data it receives for training and how it is categorized. To test the network, you must also have a set of reference images.
– You sometimes don’t get definitive data on the reason for failure. The AI deep learning algorithm can be thought of as a black box. Therefore, you can input the data, and it will produce a result. The majority of the time, all you will know is that it passed or failed apart and for what reason. As a result, it can be challenging to implement such AI vision systems in legitimate sectors like pharmaceuticals, life sciences, and medical devices.
– You need a very decent GPU & PC system for training. The amount of processing required for training the neural network cannot be handled by a standard personal computer. Your developers will need a high-end processor and a lot of memory for the graphics, but the PC used for the runtime doesn’t have to be anything special. Do not undervalue this.
Pros
– They do make good decisions in challenging circumstances. Imagine that a supplier continuously supplies a changing surface texture for your widget on your part that needs automated inspection. This would be a problem for conventional vision systems that is almost impossible to solve. This kind of application is ideal for AI machine vision.
– They are great for anomaly detection which is out of the ordinary. The capacity to spot a defect that has never been observed before and is “left field” from what was anticipated is one of the main benefits of AI-based vision systems. The algorithm in traditional machine vision systems is designed to predict a particular condition, such as a feature’s grayscale, the size of pixels that indicates a part is failing, or the color match that identifies a good part. However, the AI deep learning machine vision system may well spot a slight flaw in your part in a million that has not been accounted for, whereas the conventional machine vision system may miss it.
– They are useful as a secondary inspection tactic. You have tried every traditional image processing method, but there are still a few errors that are hard to classify against your known classification database. You have the image data, and the part fails when it should; however, you want to conduct a final analysis and drill down further to increase your yield even further. The deployment of AI deep learning would be ideal in this circumstance. You have the information, grasp the issue, and can prepare lower-goal fragments for more exact grouping. Over the next few years, AI deep learning vision adoption is likely to accelerate in this area.
– They are helpful when traditional algorithms can’t be used. You’ve tried every traditional approach to segmentation, including pixel measurement, color matching, character verification, surface inspection, and general analysis—but nothing has worked! AI can help in this situation. Deep learning ought to be tried because the consistency in the part itself is probably the reason why traditional algorithms fail.
Last but not least, the vision system application might not necessitate deep learning AI. Algorithms for traditional vision systems are still being developed. They can be used in a lot of applications where deep learning has recently emerged as the first option for meeting the need for machine vision. When applied to the right machine vision application, artificial intelligence in vision systems should be viewed as a useful complement and potential weapon.
Credits: Industrial Vision
Click on the following link Metrologically Speaking to read more such news about the Metrology Industry.